一种高性能的 Kafka 消费模型
Last updated on February 9, 2025 am
Kafka 无疑是现在最流行的消息队列。
闲话
对于消息队列的选型,在国内环境中, RocketMQ 是一个强大的对手,网络上也有各种各样的对比和指导思想,有兴趣的读者可以自行搜索查看,在本文中并不会让这两者分个高下。
网络上林林总总的文档中,比较有参考意义的是 Apache RocketMQ 官方文档中的对比:Apache RocketMQ 5.0 中文文档。
可以看到,相比之下RocketMQ 是一个更为“现代化”的消息队列中间件,原生支持了 Kafka 不具备的许多功能,同时也对 Kafka 已有的功能做了一些补充和改进。同时,从文中也可以看到 RocketMQ 相比 Kafka 有着“低延时”和“高可用”的优点,但 Kafka 相比之下拥有更高的“吞吐量”。
此外,官方文档中没有对两者的性能做出详细的说明,而阿里巴巴官方在外网发布了这篇文章作为补充:基于 Topic 数量的性能压测。
但是,就我的经验来说,在大部分实际的技术选型中,有以下三个“反直觉”的真相:
- 许多细节上的差异并不会给项目带来明显的优势。举一个实际的例子来说:在绝大部分情况下,将接口响应时间从 10s 优化至 100ms,对比将响应时间从 100ms 优化至 1ms ,给用户带来的体感是完全不同的(后者远小于前者),同时付出的成本也是完全不同的(后者远大于前者)。
- 社区活跃度的重要程度往往被我们轻视——当你遇见问题的时候,更活跃的社区往往能给你带来更短的定位 / 解决时间。这里是一个自带活跃度对比的外网社区的统计结果:社区活跃度的对比。从中可以看到,RocketMQ 在全球范围内的社区影响力远低于 Kafka。
- 不同的公司的技术选型思路有巨大的差异。举例来说,我在字节跳动工作期间,公司内部所使用的云平台是自研的“字节云”。在字节云中,从 Golang 的镜像,到云服务器的 Linux 内核,都是公司自研的——根据公司的实际情况做出了相应的优化。当时在云平台的官方文档中,基础架构的同学写下了一段大致如下的描述:“强烈推荐各业务方从 Kafka / BMQ 切换到 RocketMQ,当前字节云中的 RocketMQ 中间件从各方位对比前者都有显著的优势” 。
总的来说,所有技术选型都应该基于实际情况进行决策,到底是否应该“以牺牲部分吞吐量为代价,来获得 RocketMQ 同步刷盘的能力”,还是“它们都太差了,我要自研一款属于我的 MQ”,是需要根据实际业务场景来决定的。
而我现在所处的公司,在决策时面临的困难显然不那么强烈——我们使用亚马逊的 AWS 来部署服务,而 AWS 官方并没有提供基于 RocketMQ 的 Paas 服务,但 AWS MSK (Managed Streaming for Apache Kafka)已经相当成熟了,我们也就自然而然的选择了 Kafka 作为我们的消息队列中间件。
正文
基于 Golang 的 Kafka SDK
相同的中间件在不同编程语言中的实现的 SDK 必然是有差异的,它们往往会根据语言自身的特点做出相应的适配和优化。我所采用的 sdk 是 segmentio 公司研发的 kafka-go,是 golang 中非常流行的一个库,也是适配得较好的一个库。
这个库的实现原理大致如下:
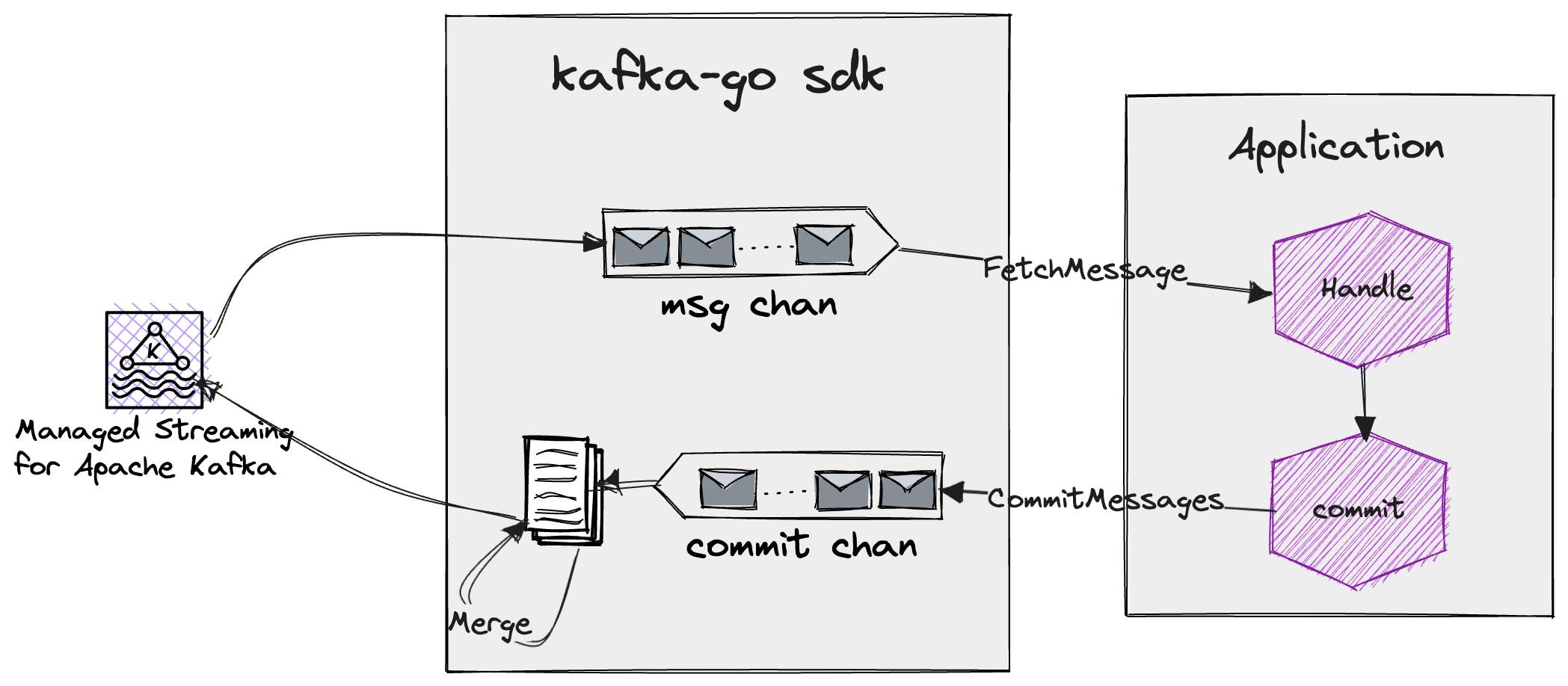
- kafka-go 会向 Kafka Broker 拉取一定数量的消息放入内存中的 msg chan(该 chan 的缓存大小是可配置的)
- 然后应用程序通过调用
FetchMessage方法来从这个 chan 中获取到一个消息并进行消费 - 当消费成功后,应用程序通过调用
CommitMessages方法来提交 commit request - 根据配置,kafka-go 会将 commit chan 中的请求立即提交,或将其 merge 合并为一个请求异步提交
简单的阻塞消费模型
最简单的消费模型其实和上面描述的过程是一致的,如下:
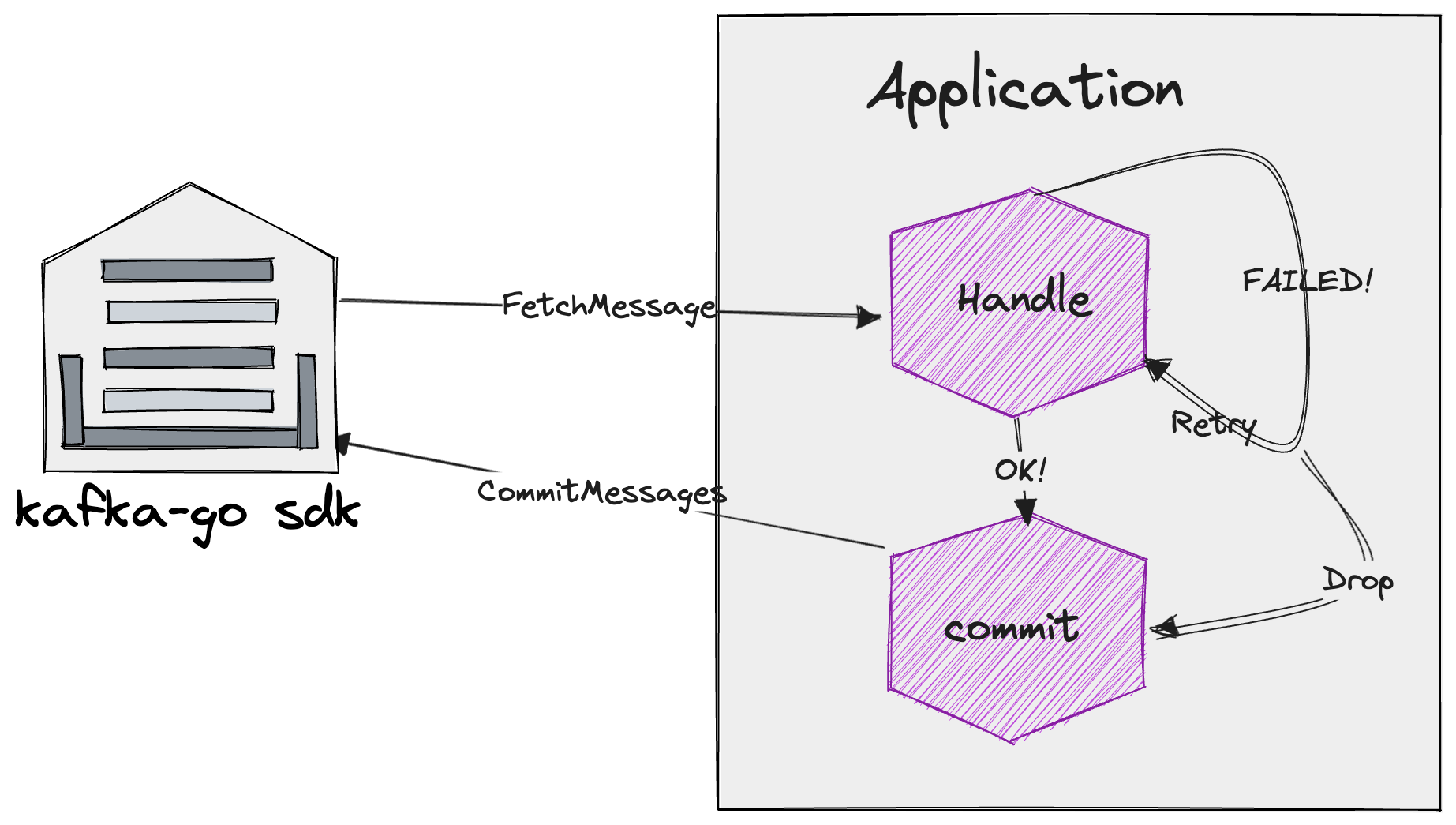
当消费成功时直接提交;当消费失败时,根据需要进行无限重试,或是直接丢弃(提交 commit 请求视为成功)。
为什么我们一定要阻塞在某一条消息的处理上,为什么不能使用一个 sync.WaitGroup 来进行一定程度的并发呢?
因为对于 Kafka 而言,它的提交行为是不区分 ACK / NACK 的,它的 commit 请求中只包含一个 offset 参数来标识当前消费者的消费进度。与此同时,kafka-go sdk 又在内存中将消息缓存到 chan 中,当我开启若干个协程调用 FetchMessage 方法时,获取到的消息是完全不同的。也就是说,当我开启三个协程处理三条消息时,可能分别在处理 offset = 1 / 2 / 3 的 3 条消息,当 1 和 2 处理失败但 3 处理成功时,一旦将 3 commit 到 Kafka 中,1 和 2 就永久的丢失了(再也不会被消费了)。
这种模型虽然很简单,但也十分低效,适合的场景也非常有限,举几个实际的例子:
- 新增 / 注销账号产生的消息。类似的场景下消息产生的 QPS 很可能 < 1,因此使用该模型并不会造成性能瓶颈,反而在一定程度上可以提升开发效率。
- 需要使用顺序消费的场景。也就是说,在消费某条消息之前,必须消费完这条消息之前的所有消息,例如涉及到某些状态流转的场景,阶段 A 不能直接转换为阶段 C,而是必须经过阶段 B,此时我们需要顺序消费 A->B、B->C 这两条消息。
高性能的批量消费模型
在 Kafka 不支持 ACK / NACK 的情况之下,如果我们仍需要保证消费的有序性,是不是就无法使用并发消费了呢?
以 Partition 为维度并发
Kafka 同一个 Topic 下的消息是分为多个 Partition 进行存储的,每个 Partition 中的消息都是按照投递的顺序进行排序的,也就是说,我们在消费同一个 Topic 的情况下,至少可以进行 Partition 维度的并发——就像在 RocketMQ 中,每个 Queue 中的消息是局部有序的。
因此,我们可以以 Partition 为维度进行并发消费。于此同时,我们还可以对于每个 Partition 都批量的拉取消息,然后进行批量的处理,但是需要消费方保证消息处理的幂等性,避免重复消费。
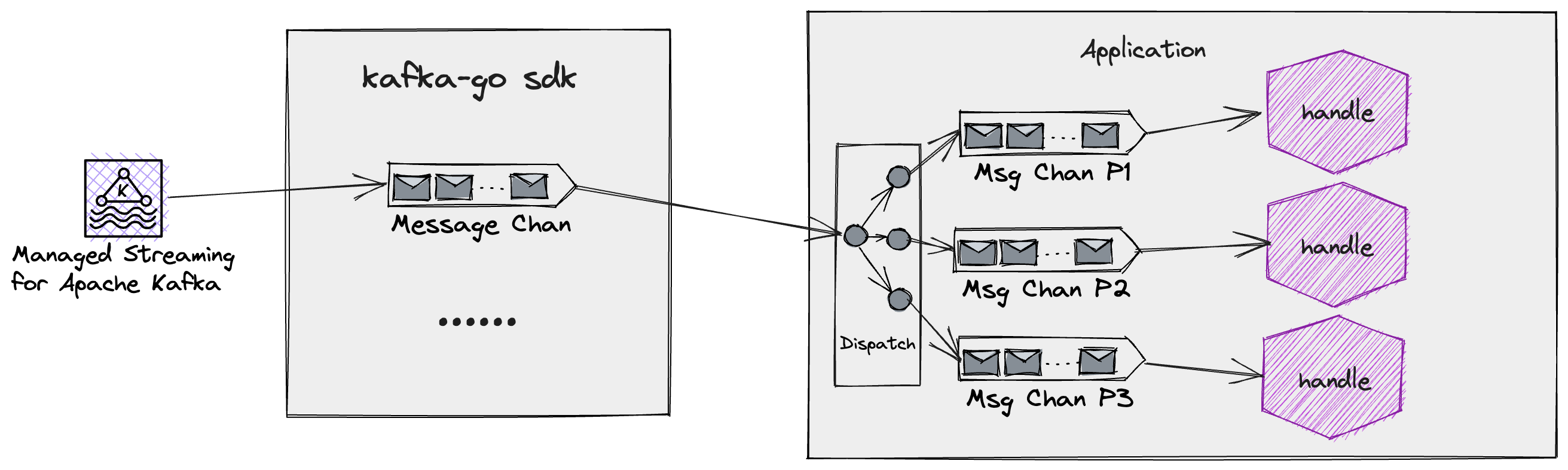
在这种模型中,我们需要做的主要有两件事:
- 实现一个简单的 Dispatcher,根据 Kafka Message 的 Partition 进行分组后,将这条消息投入对应 Partition 的 chan 中
- 实现一个通用的 Worker,用于处理 Partition Chan 中的消息
以下是我写的一段核心代码:
type KafkaConsumer[T msgtype.KafkaMessage] struct {
callback func(msgs ...T)
partitionMsgs map[int]chan T
partitionQueueSize int
minBatchSize int
maxBatchSize int
forceFlushTime time.Duration
closeCh chan struct{}
}
func (c *KafkaConsumer[T]) Run() {
go func() {
log.Info("kafka consumer started")
for {
msg := c.fetchMsg()
// 优雅退出
select {
case <-c.closeCh:
log.Info("kafka consumer stopped")
return
default:
}
c.parallelHandle(msg)
}
}()
}
func (c *KafkaConsumer[T]) Stop() {
close(c.closeCh)
}
func (c *KafkaConsumer[T]) parallelHandle(msg T) {
partition := msg.RawMessage().Partition
if _, ok := c.partitionMsgs[partition]; !ok {
c.startPartitionHandler(partition)
}
c.partitionMsgs[partition] <- msg
}
func (c *KafkaConsumer[T]) startPartitionHandler(partition int) {
// 初始化分区消息队列
c.partitionMsgs[partition] = make(chan T, c.partitionQueueSize)
// 启动分区消费者
go func() {
flushTimer := time.NewTimer(c.forceFlushTime)
for {
msgBatch := make([]T, 0, c.maxBatchSize)
// 先取一条消息, 避免直接进入计时
msgBatch = append(msgBatch, <-c.partitionMsgs[partition])
flushTimer.Reset(c.forceFlushTime)
func() {
for len(msgBatch) < c.maxBatchSize {
select {
// 超时退出
case <-flushTimer.C:
return
// 接收到新的 msg
case msg := <-c.partitionMsgs[partition]:
msgBatch = append(msgBatch, msg)
// 暂时没有新的消息到来,但也尚未超时,此时缓存的消息若满足最小接收量则退出
default:
if len(msgBatch) > c.minBatchSize {
return
}
// 再次 select, 避免空转
select {
case <- flushTimer.C:
return
case msg := <-c.partitionMsgs[partition]:
msgBatch = append(msgBatch, msg)
}
}
}
}()
// callback 中根据业务自行实现重试保证成功或是 drop
c.callback(msgBatch...)
c.CommitMessages(msgBatch...)
}
}()
}可以看到,在实际的代码实现中,会加入许多额外的细节来提供健壮性,其中使用了 map[int]chan T 结构来维护消息的分组过程,也就是实现了上述的 Dispatcher。除此之外,在 startPartitionHandler(int) 方法中,以异步的形式实现了前文中的Worker。
在 Worker 的具体实现中,我使用了 3 个可配置的选项来根据实际情况动态的调控消费行为,分别是:
forceFlushTime,每次处理消息前最大的循环时间——防止一直接收不到足量的消息而阻塞maxBatchSize,每次批量处理消息的最大数量——防止一次性接收过多消息minBatchSize,每次批量处理消息的最小数量——某些时候上游已经暂时不再产生消息,此时为了避免持续空转到超时,可以提前返回
批量发送消息
除了消费可以实现批量之外,生产也可以实现批量。
伪代码如下:
type KafkaPartitionProducer[T msgtype.KafkaMessage] struct {
brokers []string
topic string
partition int
conn *kafka.Conn
codec *kafka.CompressionCodec
logger *logrus.Entry
}
func (pp *KafkaPartitionProducer[T]) ProduceMust(msgs ...T) {
if pp.codec == nil {
panic("codec is nil")
}
if pp.conn == nil {
pp.connectMust()
}
// 构造 kafka 消息
kmsgs := make([]kafka.Message, 0, len(msgs))
for _, msg := range msgs {
kmsg := pp.buildKafkaMessage(msg)
if kmsg == nil {
continue
}
kmsgs = append(kmsgs, *kmsg)
}
if len(kmsgs) == 0 {
pp.logger.Warn("no messages to produce")
return
}
// 无限重试直到发送成功
for i := 0; ; i++ {
nbytes, _, offset, _, err := pp.conn.WriteCompressedMessagesAt(*pp.codec, kmsgs...)
if err == nil {
log.Infof("write compressed messages success")
break
}
switch err {
case kafka.MessageSizeTooLarge:
log.WithError(err).Errorf("kafka message size too large")
if len(kmsgs) <= 1 {
panic("kafka message size too large")
}
// 消息过多对半递归重发
mid := len(kmsgs) / 2
pp.ProduceMust(msgs[:mid]...)
pp.ProduceMust(msgs[mid:]...)
default:
// 其它错误直接重连
log.WithError(err).Errorf("failed to write compressed messages")
pp.connectMust()
}
}
}
func (pp *KafkaPartitionProducer[T]) connect() error {
if pp.conn != nil {
pp.conn.Close()
pp.conn = nil
}
for _, addr := range pp.brokers {
log := pp.logger.WithField("addr", addr)
ctx, canceler := context.WithTimeout(context.Background(), 5*time.Second)
defer canceler()
// 连接到指定 broker 的 topic / partition
conn, err := kafka.DialLeader(ctx, "tcp", addr, pp.topic, pp.partition)
if err != nil {
log.WithError(err).Errorf("failed to dial leader for partition")
continue
}
// 测试 kafka 连接是否正常
first, err := conn.ReadFirstOffset()
if err != nil {
log.WithError(err).Error("failed to read first offset")
conn.Close()
continue
}
last, err := conn.ReadLastOffset()
if err != nil {
log.WithError(err).Error("failed to read last offset")
conn.Close()
continue
}
log.WithFields(logrus.Fields{
"first": first,
"last": last,
}).Info("dial conn success")
pp.conn = conn
break
}
// 没有可用的 broker 连接
if pp.conn == nil {
pp.logger.WithField("brokers", pp.brokers).Error("failed to dial leader from all brokers")
return fmt.Errorf("failed to dial leader for partition %d", pp.partition)
}
return nil
}值得一提的是,上面代码中的 buildKafkaMessage 可能会成为一个瓶颈点,比如我们的构造逻辑包含一些压缩或者 IO 密集的操作。
此时我们可以使用协程池并发构造,以提升生产的吞吐量。
除此之外,它还有可能成为对于 kafka broker 的压力点,比如假设我的消息消费逻辑是一个转发逻辑,从上游获取消息后进行处理再转发给下游 kafka,我们利用上一小节的 KafkaConsumer 进行消费会构造出 Partition 级别的并发,可能会导致下游 kafka 的压力过大。
此时我们可以使用 chan 进行解耦和限流,实现并发消费+串行生产的转发模型。
消费过程的流水线
考虑到 Kafka 的消费过程本质上也是一个不同流程的串联,于是我们可以在消费过程上进一步的进行优化。
举例来说,我们的消费需要进行如下几个步骤:
- 消息内容解析,例如有的消息里面包含紧凑的二进制数据,需要进行反序列化等操作才能被程序继续处理
- 风控检查,拒绝掉不合理的消息
- 日志记录,记录消息的来临
- 业务处理,根据消息的内容进行业务处理
- 落库,将消息的处理结果落库
不难发现,其中可能有的步骤并不强烈依赖顺序处理,而有的步骤又需要。
假设我们基于前面的消费模型构建了我们的应用,那么在合理配置 Kafka 的硬件和配置参数的情况下,瓶颈将很容易的出现在上面这个消费过程上。
这里列举一个极简的优化方案:
- 我们在每一步中都使用 golang 的
chan进行解耦,比如 1 处理完之后通过chan传递给 2 继续处理。 - 而前面的每一个数字序号,都是一个单独的
goroutine,仅仅通过chan来接收消息。 - 然后对于首尾的两个环节进行特殊处理
- 首个环节需要接入 Kafka,真正的从 Kafka 中拉取消息
- 末尾环节需要将处理结果落库后,向 Kafka 提交 offset
如此一来,我们便可以实现所谓: “业务处理第一条消息时,我们的程序已经开始解析并反序列化第二条消息了”。
于是我们在消费过程中的吞吐量将会得到极大的提升。
当然,也有另外一种粗暴的方案,就是使用多个 goroutine 来批量消费一批消息,然后 wg.Wait() 等待所有消息处理完毕后再提交 offset。这种方案的优势在于实现简单,但是劣势在于无法保证消息的有序性,需要业务方自行保证消息的幂等性。
后话
Consumer Group
Kafka 的 Consumer Gourp 离不开 Rebalance 机制,所谓 Rebalance 指的就是将一个 Topic 下若干 Partition 通过协商的过程平均分配给同一个 Consumer Group 中不同 Consumer 的过程。也就是说,一个 Partition 只能被一个 Consumer Group 中的一个消费者消费,也就让我们可以容易的实现局部顺序消费,配合上 Producer 端的少许逻辑,就可以达成业务上的顺序性。
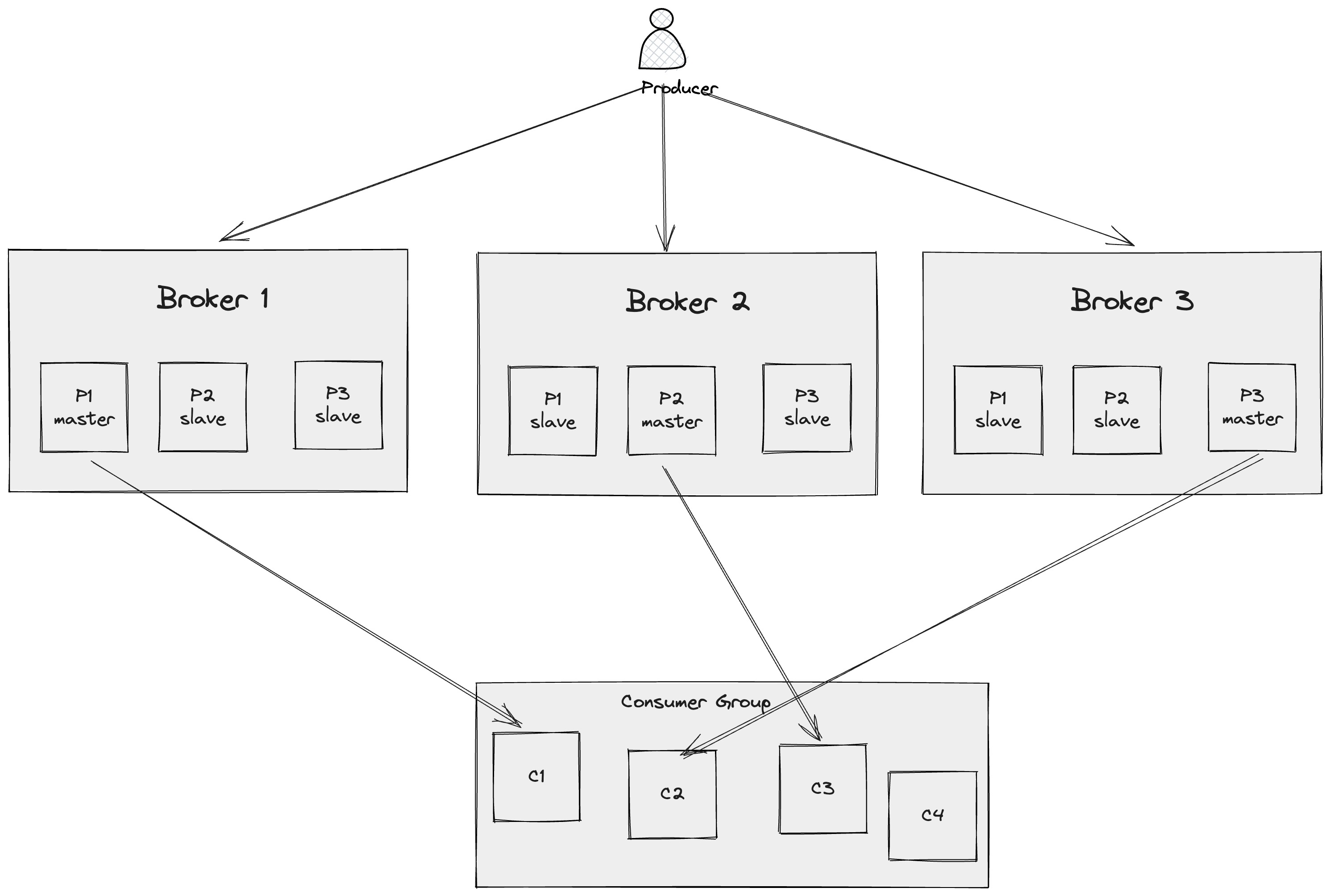
在上图中,以订单的流转为例,只需要 Producer 在生产消息时根据订单 id 分配固定的 Partition 有序的发送消息(如对于订单221,将发起订单、流转订单、完成订单三个操作依次发送到 P1 中),下游的 Consumer 就能保证同一个订单的消息被按序处理,因为同一个 Partition 中的消息不会同时被两个 Consumer 消费。
但是有些极端的情况仍可能导致重复消费的错误,例如 C1 在消费完「发起订单」后,还没来得及 Commit 就挂掉了,Rebalance 后 C2 或 C3 又会重新接收到该消息,并尝试再次发起订单,因此业务方自行保证消息消费的幂等性是十分有必要的。
Ack && Insync
Ack 的种类:
Ack = 0,producer 不需要等待任何 broker 确认收到消息的回复Ack = 1,producer 只需要等待 leader broker 确认收到消息的回复Ack = all,producer 需要等待所有 min.insync.replicas 确认收到消息的回复
Insync:
in-sync replicas (ISR) 是指能够与主节点保持同步的副本集合。这些副本需要持续跟踪主节点上的最新写入消息,并将其应用到自己的日志中。
为了避免消息写入消息后,主节点立即宕机导致的消息丢失问题,我们一般会配置 min.insync.replicas 参数,然后协同使用 Ack = all 来保证消息写入多个节点才确认。
配置思路:
上述公式能够保证我们在 N 个节点宕机的情况下,仍然能够保证系统的可用性。
举例来说,假设我们需要让某个 topic 的消息至少被 3 个节点保存(一主两从),此时我们能够接受一个(主)节点宕机,那么 min.insync.replicas 为 2。
这也就是我之前在加密货币交易所的交易系统团队工作时,内部默认的配置。(这里再次提醒,我们需要使用 Ack = all 才能与上述配置协同工作保证消息可靠)。
抄答案:
| configuration item | value | type | explain |
|---|---|---|---|
| unclean.leader.election.enable | false | brokers | disallow unclean leader election |
| replication factor | 3 | topic | we need to have at least 3 replicas |
| min.insync.replicas | 2 | topic | we need to have at least 2 in-sync replicas |
| ack | all | producer | we need to wait for all in-sync replicas to acknowledge the message |
| block.on.buffer.full | true | producer | we need to block when the buffer is full |
| broker cnt | 4 | brokers | we need to deploy 4 brokers |
注意上面 broker cnt 必须 >= replication factor,相等的情况(=3)比较好理解,每个 partition 在上述配置下,在每个 broker 都存了一份;大于的情况下,有的 broker 未必会有某个 partition 的数据。
也就是说,当我们配置的 broker 多于 replication factor 数量时,主要起到下面两个作用:
- 减轻每一个 broker 的压力,因为每个 broker 上需要 handle 的 partition 数量变少了。
- 假设一个 broker 挂掉,它可能对某些 partition 的消费完全没有任何影响,因为它没有存储这个 partition 的数据。
吞吐量 vs 延迟:
除上述之外,还有部分用于提升 Kafka 消费吞吐量的配置(注意,提升吞吐量的同时往往都会造成延迟的增加,请根据业务选择)
- producer
linger.ms, default 0, 消息在缓冲区中的停留时间, 增大该值可以等待更多消息加入批次,提高吞吐量,但也会增加延迟。batch.size, default 16KB, 一次批量发送消息的大小, 增大该值可以减少网络开销,提高吞吐量,但也会增加延迟。buffer.memory, 生产者本地缓冲区大小, 用于存储待发送的消息。适当增大可以提高吞吐量,但过大会增加内存使用风险。
- broker
socket.send.buffer.bytes / socket.receive.buffer.bytes, 控制生产者与代理、代理与消费者之间的网络缓冲区大小(默认值 100 KB)。log.segment.bytes, 日志分段文件大小。适当增大可以减少文件数量,提高磁盘写入性能,但也会增加延迟。log.buffer.size, Kafka 日志文件缓存大小,与底层 I/O 性能相关。
- consumer
fetch.min.bytes / fetch.max.bytes, 定义消费者每次拉取的最小/最大数据量,增大可以减少请求次数,提高吞吐量。