理解 Golang context.Context
Last updated on September 23, 2023 pm
Go 在 1.7 版本中引入了标准库 context,现在在各大开源库中已经变得随处可见。
本文基于 go1.21.1 darwin/arm64 源码编写。
入门 Context
Context 是什么?
在 context.go 文件的开头,Go Authors 定义了主角 Context interface ,并对其做出了如下描述:
A Context carries a deadline, a cancellation signal, and other values across API boundaries.
Context’s methods may be called by multiple goroutines simultaneously.
也就是说,Context 具备如下 4 个功能:
- 可以携带用于控制「超时」的 Deadline 信息
- 可以携带用于控制「取消」的 Signal 信息
- 可以携带自定义数据
- 可能被多个
goroutine并发调用
从这几个基本功能及其命名中,我们可以大致看出,Context 是一个数据结构,它不仅可以用于保存自定义的数据,还额外携带了被动超时和手动取消的功能,除此之外,它本身还是并发安全的 —— 我们该如何运用起来?它对我们的编程有什么实际的帮助?
Context 的基本编程范式
前面我们已经了解到 Context 的大致概念,接下来我们将目光放在代码层面,看看这个数据结构在 Go 语言中基本的编程范式是怎样的。
在 Golang 官方的文档中,明确地指出了 context.Context 的使用场景:
Incoming requests to a server should create a Context, and outgoing calls to servers should accept a Context. The chain of function calls between them must propagate the Context …
一个服务器收到请求之后,应该创建一个 Context ,而下游的服务器也应该接受一个 Context ,在函数调用链中,Context 也应该不间断的被传递。
也就是说,Context 这个数据结构,应该伴随一整个请求的完整链路:
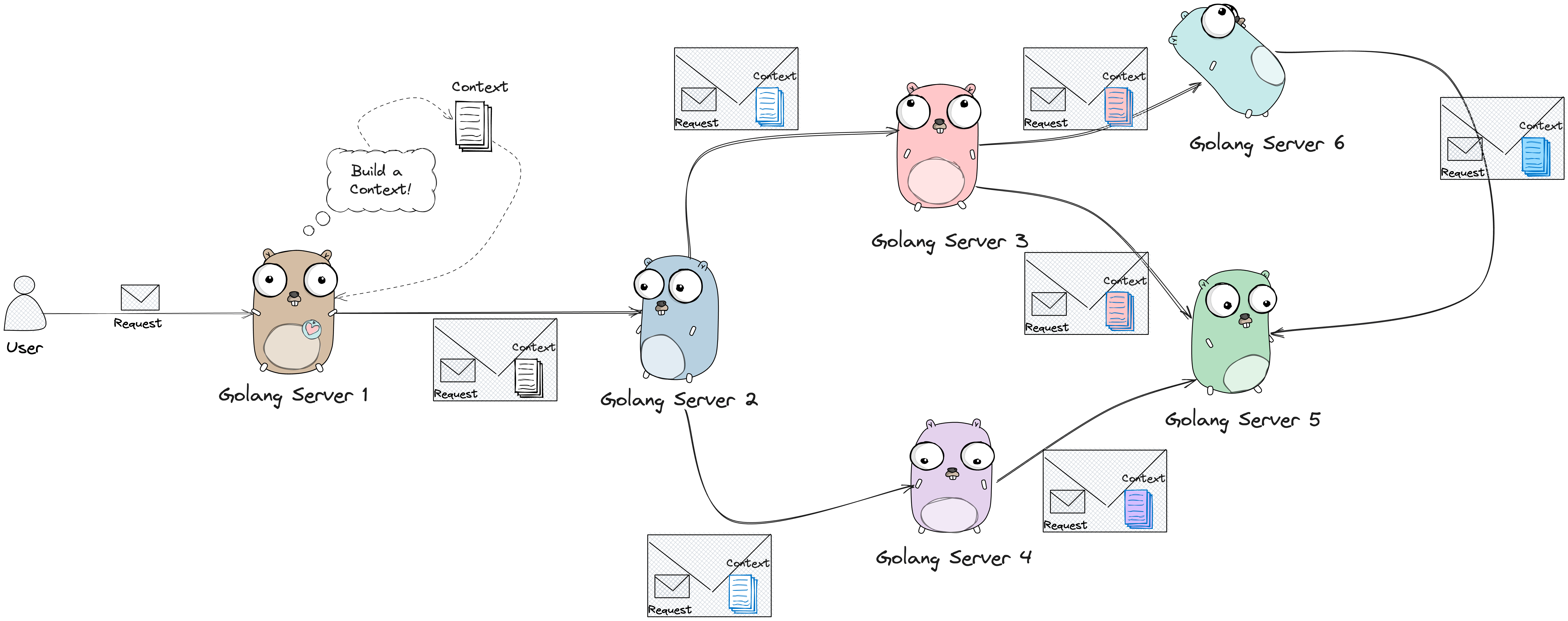
除此之外,在服务的内部,Context 也应该在函数调用链中不断的被传递:
func main() {
ctx := context.Background()
chainRoot(ctx, ...)
}
func chainRoot(ctx context.Context, ...) {
...
chainSecond(ctx, ...)
...
}
func chainSecond(ctx context.Context, ...) {
...
chainThird(ctx, ...)
...
}
func chainThird(ctx context.Context, ...) {
...
}至此,我们对 Context 的基本使用方式有了一个基本的了解 —— 将其放在函数参数列表中的第一位,然后在编码时手动传递。在跨服务调用的场景下,我们应该将 ctx 序列化后伴随请求传递到下游服务中,下游服务再将其反序列化出来继续使用。
此外,从上面的代码中,我们也不难理解为什么在 Golang 官方的注释中描述道:Context 可能被多个 goroutine 并发调用 —— 在整个调用链中,我们很有可能开启若干协程来处理业务,且每个协程都对 Context 都具备访问权限。
Context 的具体使用
通过上面的描述,我们已经大致了解到 Context 在实际编码中的编程范式 —— 作为参数进行传递。一些有经验的程序员在初见时,自然而然会觉得:“这不是在对代码造成侵入吗?”,就像 Golang 中处理错误的方式一样,也会有人觉得这十分不优雅。
让我们先抛开这些“审美观念”不谈,把目光先聚焦在 Context 的具体使用方式上,看看它能对我们的编程过程带来多大的帮助。理解了它真正能起到的作用之后,我们再根据实际业务情况来做权衡也不迟。
接下来根据第一节中提到的前三种数据承载的能力,我们分别给出相应的 demo 进行演示。
1. 传递自定义数据
我们可以使用 context.Background() 来获得一个初始化的 Context,再使用 context.WithValue() 来给一个现有的 Context 注入自定义数据:
func main() {
ctx := context.Background()
ctx = context.WithValue(ctx, "key1", "value1")
ctx = context.WithValue(ctx, "key2", errors.New("value2"))
ctx = context.WithValue(ctx, "key3", 3)
fn(ctx)
}
func fn(ctx context.Context) {
println(ctx.Value("key1").(string))
println(ctx.Value("key2").(error).Error())
println(ctx.Value("key3").(int))
}从这段代码中可以看出,Context 的行为就像是一个 map[string]any ,我们在获取数据时可能会需要用到类型断言。
传递自定义数据相关的使用比较简单,这里不再展开。
2. 用于超时控制
很多时候,我们需要对一个过程(可以是本地函数调用,也可以是远程过程调用)设置好时间的限制,避免其运行太久。
我们可以使用如下四个函数来给一个 Context 注入超时信息:
context.WithTimout()context.WithTimeoutCause()context.WithDeadline()context.WithDeadlineCause()
其中,函数末尾带有 Cause 意味这你可以「自定义一个超时错误」传入函数中,当发生超时的时候 Context 会将这个自定义错误返回出来,否则它会返回一个默认的超时错误。
并且,WithTimout* 本质上是 WithDeadline* 的一个封装,封装过程也极其简单,即:将 time.Duration 与 time.Now 求和从而计算得出 Deadline。
func main() {
ctx := context.Background()
// 给 ctx 设置 3s 后超时
ctx, cancel := context.WithTimeout(ctx, time.Second*3)
go func() {
defer cancel()
longTimeWork(ctx)
}()
// ctx 超时结束后,从中获取导致其结束的 err 信息
select {
case <-ctx.Done():
println("main:", ctx.Err().Error())
}
}
func longTimeWork(ctx context.Context) {
for i := 1; ;i++ {
select {
case <-ctx.Done(): // 监听超时信号
return
default: // 未超时则继续处理业务逻辑
println("doing sth inside", i)
time.Sleep(time.Second)
}
}
}Output:
doing sth inside 1
doing sth inside 2
doing sth inside 3
main: context deadline exceeded代码解析:
在上面的例子中,我们在外层设置了一个过期时间为 3 秒的 Context ,然后将这个 Context 作为参数传递给了一个耗时很长的函数,该函数内部不断监听着这个 Context 的超时信号,当超时发生时立即退出。
最后在外层,我们监测到 Context 超时后,可以通过 Context.Err() 来获取错误信息,即输出中的 context deadline exceeded。
思考:
仔细观察上面对于超时过程的监控过程,我们不难发现,对于超时信号的监控侵入了 longTimeWork 的代码实现。
这种方式看起来让我们的代码变得不够优雅,但它也给我们带来一个好处 —— 极细粒度的超时检测,例如我们可以将代码改写为下方这样:
func longTimeWork(ctx context.Context) {
// 封装一个判断是否超时的函数
timeouted := func() bool {
select {
case <-ctx.Done():
return true
default:
return false
}
}
subwork1(...)
if timeouted() {
return
}
subwork2(...)
if timeouted() {
return
}
subwork3(...)
if timeouted() {
return
}
// ...
}可以看到,我们甚至可以将检测超时的粒度细分为「行级」,每执行一行代码就检测一次。
通过 Context 赋予我们的超时机制,我们可以用一行代码为基本单位来实现细粒度的超时检测(粒度可以从 1 行到 n 行),在 Context 的帮助下,我们可以容易地避免掉大量无意义的运算行为。
3. 用于手动终止
在上一节中,我们看到了基于超时的行为控制,但有时我们的业务逻辑可能需要更精准的控制,例如:虽然现在还尚未超时,但是我当下就想立马取消后续的所有运算。
比如 javascript 中 Promise.Race() 就是一个很好的例子。我们有时会开启多个异步任务让他们进行“比赛”,任何一个任务完成都意味着这场比赛已经结束,因为我们已经拿到了我们想要的计算结果,此时别的任务再进一步去做运算已经失去了意义,这时我要是能手动取消这些任务就能节省大量的运算资源。
在 Context 中,我们可以使用context.WithCancel 来给 Context 设置一个手动取消的信号监听器:
func main() {
ctx := context.Background()
ctx, cancel := context.WithCancel(ctx)
go longTimeWork(ctx)
// 3s 后手动取消
timer := time.NewTimer(time.Second * 3)
select {
case <-timer.C:
cancel()
}
select {
case <-ctx.Done():
println("main:", ctx.Err().Error())
}
}
func longTimeWork(ctx context.Context) {
for i := 1; ; i++ {
select {
case <-ctx.Done():
return
default:
println("doing sth inside", i)
time.Sleep(time.Second)
}
}
}Output:
doing sth inside 0
doing sth inside 1
doing sth inside 2
main: context canceled可以看到,这次我们在外层等待 3s 后手动调用 cancel()取消了异步任务,而之前是在外部仅设置超时时间,ctx 内部自主取消,差别还是比较明显的。
同样,内部响应取消信号的粒度与之前前文是一致的,可以进行自定义,甚至可以忽略这个信号 —— 只要你不去监听 ctx.Done() 即可。
4. 综合使用
我们在实际应用的过程中,可以将前面提到的若干特性结合起来一并使用。
这里举一个实用的例子:
我们往往在生产环境会部署若干个服务,用户的请求会经过网关到达一个又一个的服务,最后经过一系列处理后返回结果给客户端。
此时我们面临着若干的问题:
网关设置的超时时间如何与后端服务进行联动?
注意,网关虽然有自己的超时时间,在超时发生时,网关会拒绝等待后端服务的响应,直接给用户返回 HTTP 504 错误。但是此时如果后端服务没有感知到这一点,就会继续进行无意义的处理和运算,最终返回给网关的结果也会被网关丢弃,造成不必要的资源浪费。同理,服务调用链上的每个节点之间也都面临相同的问题,不局限于网关和网关的下一跳节点。
通用数据的传递有没有更简洁的方式?
客户端发起的请求,在处理过程中往往需要很多额外的信息(请求本身的信息可能并不足够),这些信息往往在前置的节点中会被查询出来,然后捎带给下游节点。但是,在服务内部的函数调用链上,如何将所有这些额外的数据进行传递呢?一种简单方式就是将这些中途得到的信息以参数的形式传给函数内部,但是这可能随着数据种类的增多,导致函数的参数列表变得臃肿。
能不能灵活的终止进行中的任务?
与前面「用于手动终止」一节提到的原理类似,仅仅依赖超时时间来进行流程控制是不够灵活的,我们希望可以自己决定何时终止。
下面给出一段伪代码演示综合使用的方式(实际使用中可能会封装得更加抽象和优雅,这里只做展示用)
- 代码使用了
gin框架作为 http 服务器 - 我们首先定义了通用的数据和特定接口的请求体
- 然后编写了一个中间件用于前置解析请求并生成
ctx - 随后在接口的 handler 中我们可以直接获取到解析好的
ctx并传递给业务函数进行使用了
type BaseCtx struct {
UserID string `json:"userID"`
AccountID string `json:"accountID"`
}
type UserRequest struct {
Username string `json:"username"`
}
// Middleware 解析请求中的 JSON 请求体并将参数存储到 Context 中
func ContextMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
// 读取请求体
body, err := io.ReadAll(c.Request.Body)
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "Failed to read request body"})
c.Abort()
return
}
// 将请求体重新放回请求中
c.Request.Body = io.NopCloser(bytes.NewBuffer(body))
// 解析 JSON 请求体到 BaseCtx 结构
var baseCtx BaseCtx
if err := json.Unmarshal(body, &baseCtx); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "Failed to parse JSON"})
c.Abort()
return
}
// 将参数存储到 Context 中
ctx := context.WithValue(context.Background(), "userID", baseCtx.UserID)
ctx = context.WithValue(ctx, "accountID", baseCtx.AccountID)
// 将新的 Context 替换原有的 Context
c.Request = c.Request.WithContext(ctx)
// 继续处理请求
c.Next()
}
}
func main() {
r := gin.Default()
// 注册解析 ctx 的中间件
r.Use(ContextMiddleware())
r.POST("/user", func(c *gin.Context) {
// 获取 Context
ctx := c.Request.Context()
// 超时时间为 5 秒
ctx, cancel := context.WithTimeout(ctx, 5*time.Second)
defer cancel()
// 读取请求体
body, err := io.ReadAll(c.Request.Body)
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": "Failed to read request body again"})
c.Abort()
return
}
userReq := &UserRequest{}
if err := json.Unmarshal(body, userReq); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "Failed to parse JSON again"})
c.Abort()
return
}
// 在处理程序中使用 ctx 和请求体
println(ctx, userReq)
c.String(http.StatusOK, "ok")
})
r.Run(":8080")
}上面大致演示了一下在实际生产中如何使用 ctx,一般来说,我们会在接到请求后利用一些中间件来提前做好解析,包括配置好当前请求的超时时间等,后续在业务逻辑相关的代码中就可以拿来即用了。
当然,需要注意的是,我们在业务逻辑中可能会调用下游服务,此时我们还需要在调用下游服务前实现一个类似的中间件,将 ctx 中必要的参数序列化到请求中,从而可以传递到下游中去。
但是,我们不难发现 ctx 中非常规的数据是无法进行序列化的,例如 function 、chan 等,甚至包括设置好的超时监听器。因此,我们可能需要将超时时间等信息,以时间戳或字符串的形式进行序列化,这些同样可以封装在中间件的逻辑中。
Context 原理
前面介绍了 Context 的使用方式,接下来介绍 Context 的实现原理。
接口定义
Context 本身是一个接口,对外提供的方法比较少,常用的方法已经在上文演示过了:
ctx.Done(),用于监听取消 / 超时信号ctx.Err(),用于获得取消 / 超时的原因ctx.Value(),用于获得自定义数据
除此之外还有一个方法叫做 Deadline() (ddl time.Time, ok bool),这个方法用于获得设置好的超时时间。
实现类
既然是一个接口,那么就应该有相对应的实现:
valueCtx,对应context.WithValue(),是一个用于承载自定义数据的实现。timerCtx,对应context.WithDeadline*|WithTimout*(),是一个用于承载超时逻辑的实现。cancelCtx,对应context.WithCancel*(),是一个用于承载取消逻辑的实现。
继承关系
从上面的几个 context.With*(parent Context) 方法的参数定义中,我们发现 Context 与 Context 之间是存在继承关系的,比如:
func main() {
ctx := context.WithValue(context.Background(), "k1", "v1")
ctx, _ = context.WithTimeout(ctx, 5*time.Second)
}这段代码能够生成一个既带有自定义数据 <k1, v1> 又带有超时时间 5*time.Second 的 Context。
由此,我们从最简单的 valueCtx 开始,先探寻 Context 之间的继承关系是如何实现的。
valueCtx
type valueCtx struct {
Context
key, val any
}
func WithValue(parent Context, key, val any) Context {
if parent == nil {
panic("cannot create context from nil parent")
}
if key == nil {
panic("nil key")
}
if !reflectlite.TypeOf(key).Comparable() {
panic("key is not comparable")
}
return &valueCtx{parent, key, val}
}可以看到,valueCtx 本身就是一个单链表结构,通过内部的 Context 字段指向父节点来完成一个反向的连接。
当我们连续调用三次 context.WithValue 时,如下:
func main() {
ctx := context.Background()
ctx = context.WithValue(ctx, "k1", "v1")
ctx = context.WithValue(ctx, "k2", "v2")
ctx = context.WithValue(ctx, "k3", "v3")
}会得到一个如图所示的链表结构,很好理解:
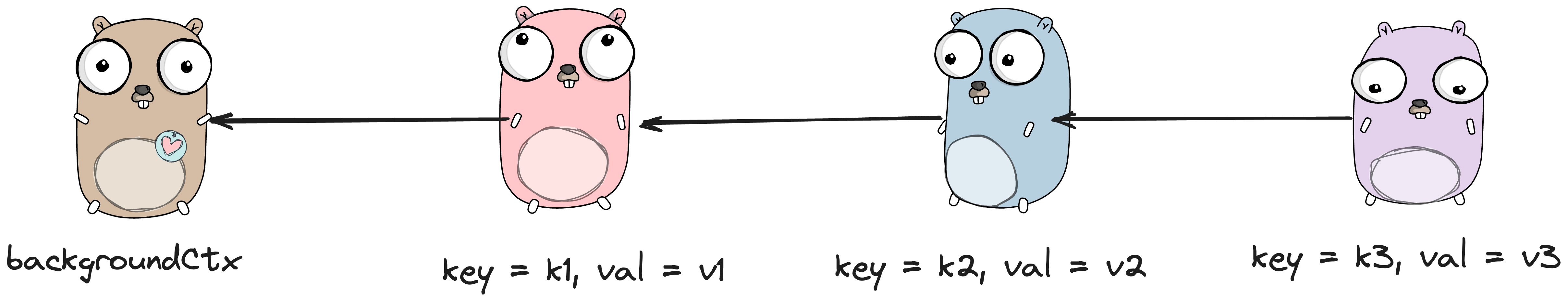
也就是说,当我们调用 Context.Value(key string) 的时候,我们会从当前的 valueCtx 一路往前寻找,直到链表的首节点为止:
func (c *valueCtx) Value(key any) any {
if c.key == key {
return c.val
}
return value(c.Context, key)
}cancelCtx
type cancelCtx struct {
Context
mu sync.Mutex // protects following fields
done atomic.Value // of chan struct{}, created lazily, closed by first cancel call
children map[canceler]struct{} // set to nil by the first cancel call
err error // set to non-nil by the first cancel call
cause error // set to non-nil by the first cancel call
}这里变得稍微复杂一些了,但是我们可以发现,反向链表的数据结构仍然得到了保留,多余的字段都是用于服务 cancel 功能的。
那么我们看一看 context.WithCancel() 做了什么,是如何初始化一个 cancelCtx 并用它构建起一个链表节点的:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
c := withCancel(parent)
return c, func() { c.cancel(true, Canceled, nil) }
}
func withCancel(parent Context) *cancelCtx {
if parent == nil {
panic("cannot create context from nil parent")
}
c := &cancelCtx{}
c.propagateCancel(parent, c)
return c
}
func (c *cancelCtx) propagateCancel(parent Context, child canceler) {
c.Context = parent
done := parent.Done()
if done == nil {
return // parent is never canceled
}
...
if p, ok := parentCancelCtx(parent); ok {
// parent is a *cancelCtx, or derives from one.
p.mu.Lock()
if p.err != nil {
// parent has already been canceled
child.cancel(false, p.err, p.cause)
} else {
if p.children == nil {
p.children = make(map[canceler]struct{})
}
p.children[child] = struct{}{}
}
p.mu.Unlock()
return
}
...
// 这里实现了取消的逻辑
go func() {
select {
case <-parent.Done():
child.cancel(false, parent.Err(), Cause(parent))
case <-child.Done():
}
}()
}上面的代码可能看起来比较复杂,但是本质上实现了一个大致如下的功能:
- 将当前的
cacelCtx与链表中与自己最近的父级cancelCtx关联起来 - 开启一个
goroutine监听父级cancelCtx的取消信号
也就是说,当一个可以进行取消操作(比如 valueCtx 就不具备取消功能)的 ctx 被取消时,它在链表上的所有关联起来的子级 ctx 也会被取消。
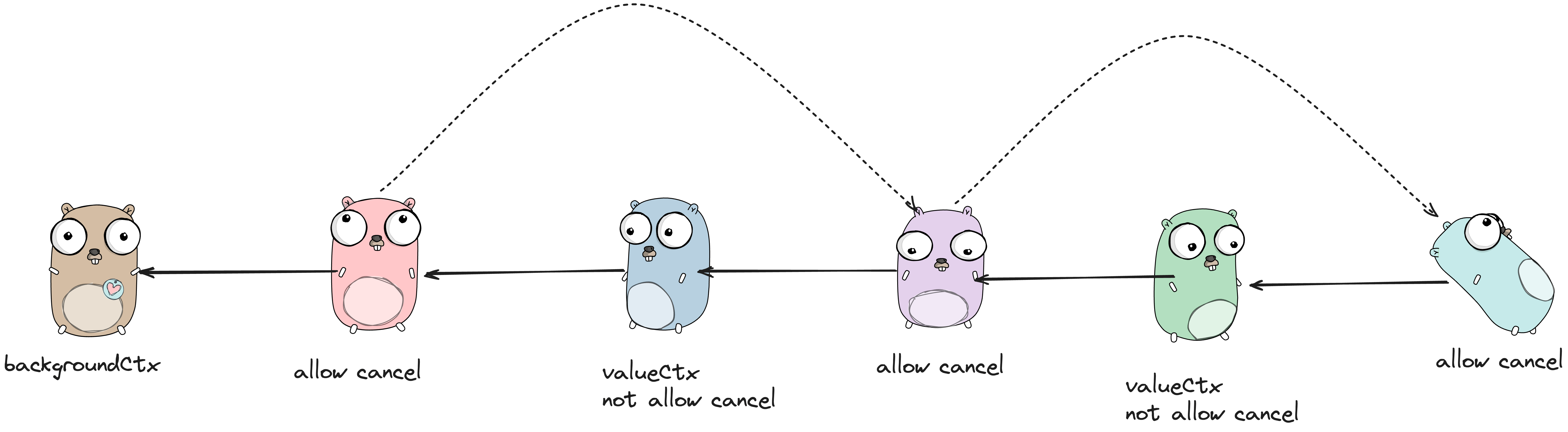
从上图可以看到,cancelCtx 在链表上与自己最近的父级 cancelCtx 建立起了一个正向的关联,这个关联正是使用 children map[canceler]struct{} 字段来实现的。
有了这个关联关系,当父级节点进行 cancel() 操作时,所有的可以取消的子级节点也会被 cancel()。但是反过来则不行,也就是说一个子级节点取消后并不会影响它的父级节点。
具体的取消实现逻辑这里略过,Golang 本身利用了原子变量和锁机制保证了并发安全,最终实现的目标便是在 cancelCtx.done 中安全的放入一个已经被关闭的 chan,从而让外界能够通过 <-ctx.Done() 语法来感知到当前 ctx 已经被取消了;同时还给 ctx.err 赋予了对应的信息,外界便可以通过 ctx.Err() 来获取到这个信息。
timerCtx
type timerCtx struct {
cancelCtx
timer *time.Timer // Under cancelCtx.mu.
deadline time.Time
}从定义中,我们不难看出,timerCtx 继承了 cancelCtx,也就是说 timerCtx 也是「可取消」的 Context,在上面图中的链表结构中,它的关联方式与 cancelCtx 是保持一致的。
只不过,timerCtx 本身还依赖于一个额外的 timer *timer.Timer 来实现它的超时逻辑。
func WithDeadlineCause(parent Context, d time.Time, cause error) (Context, CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
...
c := &timerCtx{
deadline: d,
}
c.cancelCtx.propagateCancel(parent, c)
...
c.mu.Lock()
defer c.mu.Unlock()
if c.err == nil {
// 注意这里,timer 中的 goroutine 在到期之后会调用这个 cancel 方法
c.timer = time.AfterFunc(dur, func() {
c.cancel(true, DeadlineExceeded, cause)
})
}
return c, func() { c.cancel(true, Canceled, nil) }
}从上面的代码中可以看到,整体上 timerCtx 与 cancelCtx 行为保持一致,但是利用了一个 time.Timer 启动了一个额外的 goroutine 来实现超时之后自动调用 cancel() 的逻辑。
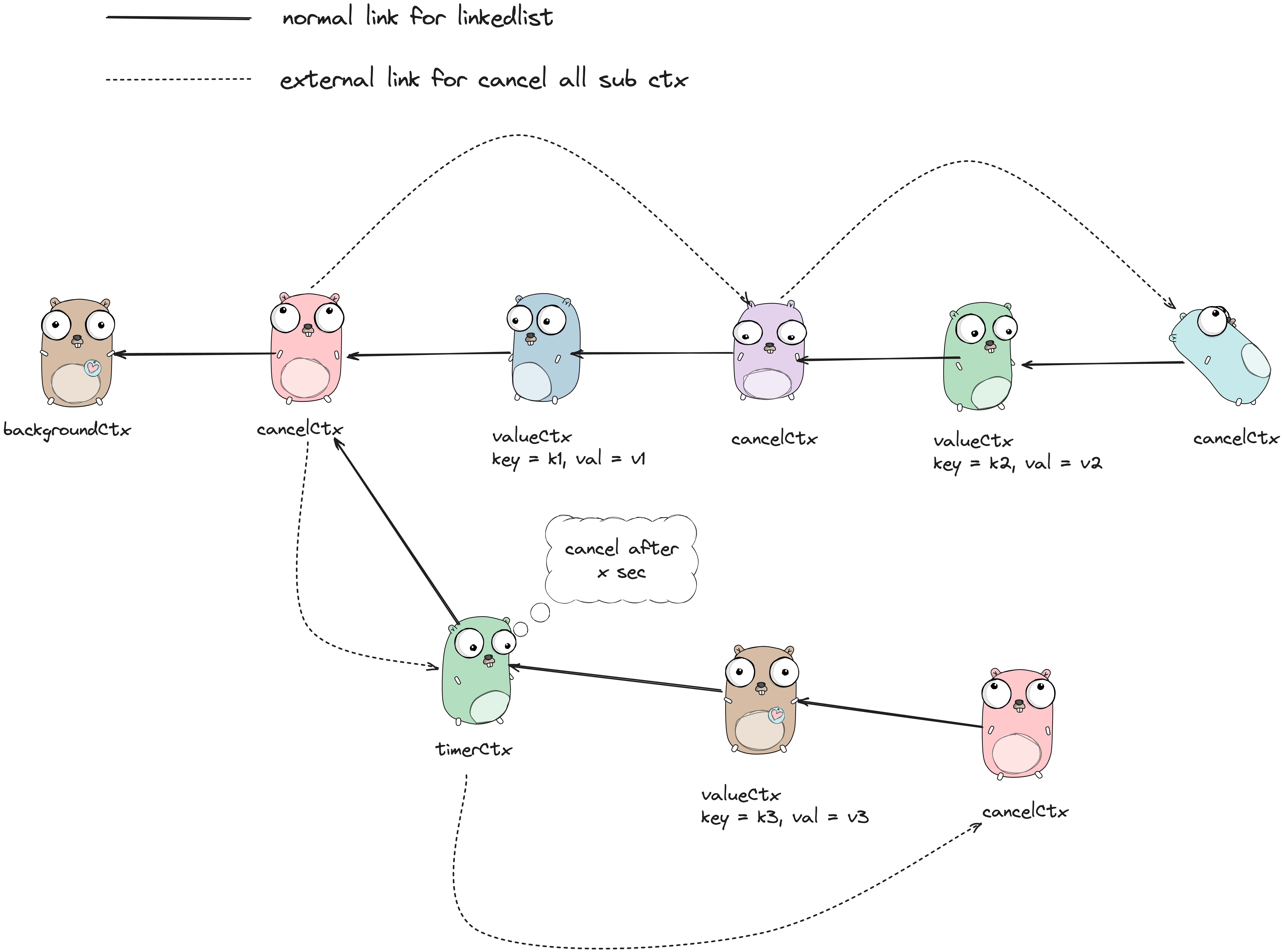
至此,我们的 Context 继承关系大致如下所示:
后话
不管 Context 使用起来是否优雅,毋庸置疑的是它是 Golang 团队官方提出的编程范式和解决方案,我在字节跳动工作期间,整个团队都在以规范的方式使用着 Context。
具体来说,有以下几个典型的应用场景:
- 我们会使用 Context 来传递一些在网关层就可以使用插件植入的 “租户/ 用户 ID” 以及 “租户密钥” 之类的数据,配合
gorm框架提供的回调功能,可以让业务无感知的情况下,进行数据库查询条件的修改,以及写前加密、读后解密的逻辑。 - 字节跳动开源的
KiteXRPC 框架(Link)中,实现了 Context 的自动序列化 / 反序列化,让业务方无感知的就能够获取并传递 Context。 - 团队的基建中,也依赖 Context 进行流量染色和链路追踪的功能。
- …
Golang 官方对于 Context 的使用还有诸多建议,就个人而言,我认为最需要注意的是我们不应该将 Context 视为一个万能的参数传递容器,否则将导致代码的可读性和可维护性大打折扣 —— 试想如果项目中所有函数都如下定义该是多么可怕的一件事:
func Xxx(ctx context.Context)
func Yyy(args map[string]any)PS:我目前所在的团队从不使用 Context(虽然我本人非常倾向使用),链路上也没有通过 TracingId / LogId 之类的参数进行串联,但是就目前来看,这也没有对我们的运维和迭代造成太大的困扰。
总而言之,Context 不是银弹,但它已经证明了它的强大。